Introduction
Natural Language Processing (NLP) has witnessed remarkable advancements in recent years, with machine-generated text playing a pivotal role in tasks such as machine translation, summarization, and text generation. Evaluating the quality of these generated texts is crucial, and one of the widely adopted metrics for this purpose is BLEU (Bilingual Evaluation Understudy).
BLEU Metric Overview
BLEU, introduced as a metric for machine translation evaluation, has since become a standard in assessing the efficacy of various NLP models. Its core principle involves comparing the similarity between the machine-generated text and one or more human-generated reference texts.
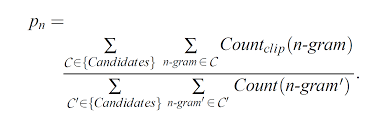
The formula you've presented is part of the computation for the BLEU (Bilingual Evaluation Understudy) score, a metric commonly used in natural language processing (NLP) and machine translation evaluation. This formula specifically addresses the calculation of the precision component of the BLEU score
Precision Calculation
At the heart of BLEU lies precision calculation. The metric assesses how well the generated text aligns with the reference texts, employing n-grams (sequential word sequences) for the comparison. BLEU measures precision by counting overlapping n-grams, where n can vary from unigrams to higher-order n-grams like bigrams or trigrams.
Modified n-gram Precision:
BLEU considers modified precision for different n-grams, contributing to a nuanced evaluation. By incorporating multiple n-grams, the metric provides a more comprehensive assessment of the generated text's quality.
Example
To illustrate the workings of the BLEU metric, let's consider a machine translation task where the goal is to translate the English sentence "The cat is on the mat" into French. Assume the machine generates the following output: "Le chat est sur le tapis."
Precision Calculation:
This can be Done using Huggingface Dataset Module
""""
from datasets import load_metric
import numpy as np
bleu_metric = load_metric("sacrebleu")
bleu_metric.add(prediction="the the the the the the", reference=["the cat is on the mat"])
results = bleu_metric.compute(smooth_method="floor", smooth_value=0)
results["precisions"] = [np.round(p, 2) for p in
results["precisions"]]
This is Playground for more info
Limitations and Considerations
While BLEU is a valuable metric, it is not without limitations. BLEU primarily focuses on surface-level similarities and does not capture semantic meaning or fluency in the generated text. Therefore, using BLEU in conjunction with other evaluation metrics is advisable for a more well-rounded assessment.